Recent improvements in large language model (LLM) performance on academic benchmarks, such as MATH and GSM8K, have
emboldened their use as standalone tutors and as simulations of human learning. However, these new applications require more than the ability
to generate problem solutions. To evaluate these applications more directly we introduce TutorGym, a standardized interface for testing artificial
intelligence (AI) agents within existing intelligent tutoring systems (ITS) that have been tested and refined in classroom studies, including
CTAT tutors, Apprentice Tutors, and OATutors.
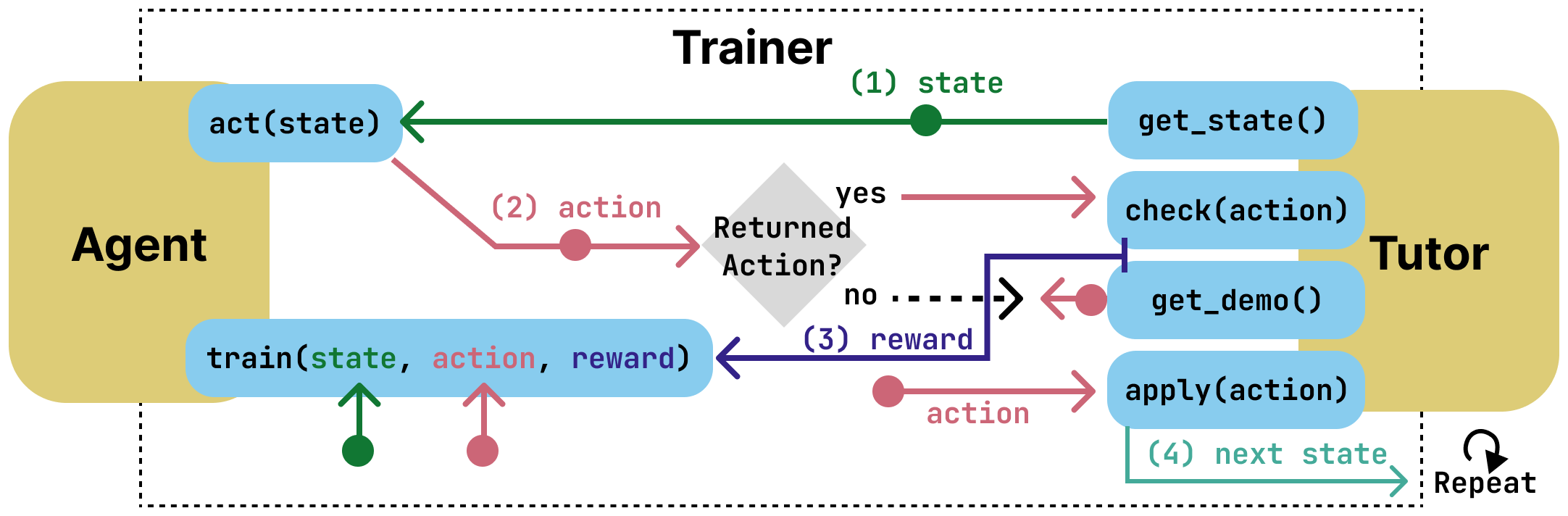
TutorGym is more than a simple problem-solution benchmark, it situates AI agents within the
interactive interfaces of existing ITSs. At each step of problem-solving, AI agents are asked what they would do as a tutor or as a learner. As
tutors, AI agents are prompted to provide tutoring support—such as generating examples, hints, and step-level correctness feedback—which can
be evaluated directly against the adaptive step-by-step support provided by existing ITSs. As students, agents directly learn from ITS instruction,
and their mistakes and learning trajectories can be compared to student data.
TutorGym establishes a common framework for training and evaluating diverse AI agents, including LLMs, computational models
of learning, and reinforcement learning agents, within a growing suite of learning environments. Currently, TutorGym includes 223 different
tutor domains. In an initial evaluation of LLM-based agents with TutorGym, we find that LLMs are relatively poor at tutoring in TutorGym's
ITS interfaces, but show a remarkable ability to produce learning curves similar to human learning curves when trained against those ITSs with
in-context learning.